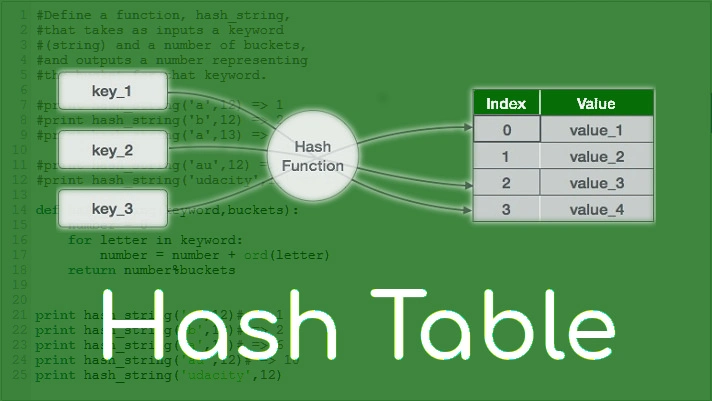
Hash Table là gì?
HashTable (một số ngôn ngữ lập trình còn gọi là Map, Dictionary) là một cấu trúc dữ liệu dạng key-value pairs. Nó phù hợp cho việc thêm dữ liệu và truy vấn dữ liệu. Nó được sinh ra để khắc phục yếu điểm của 2 thằng Dynamic Array và Linked List (bằng cách implement 2 thằng này bên trong HashTable)
Chắc hẳn bạn đã biết ưu và khuyết điểm của 2 thằng Dynamic Array và Linked List
-
Dynamic Array:
- Thêm phần từ : worst-case trường hợp xấu nhất là array đã đầy và mình phải x2 dung lượng array lên => O(n)
- Truy cập phần tử : array mà O(1) constant-time xịn nhưng mà bạn phải nhớ index (số) của phần tử muốn truy cập.
-
Linked List:
- Thêm phần tử : O(1) gán next của phần tử đuôi = new Node (code : tail.next = new Node(val); tail = node)
- Truy cập phần tử : duyệt qua cả list nên O(n)
-
HashTable :
- Thêm phẩn tử : O(1).
- Truy cập phần tử : "gần như" Ω(1) trong trường hợp tốt nhất, O(n) trong trường hợp xấu nhất nhưng mà ta sẽ có lợi thế ở constant factor, vì ta sẽ ko phải loop qua n phần tử mà có thể là n/100 hoặc n/1000 => nên thực tế khi chạy nó nhanh hơn O(n). Nice thing là bạn có thể truy cập phần tử bằng key (string) dễ nhớ hơn so với index chứ?
Ứng dụng của HashTable.
- Book index.
- DNS phân giải tên miền: cloudfare.com -> 1.1.1.1
- Database, lưu trữ dữ liệu dạng key-value : danh bạ, số tài khoản ngân hàng...
- ...
"Không có nhẫn thuật nào là hoàn hảo" ha? Itachi said.
Nghe có vẻ HashTable là một vũ khí toàn năng khi các operation của nó "gần như" constant-time O(1). Mấu chốt nằm ở cái từ "gần như", để HashTable thêm và truy cập phần tử có thể được coi constant-time O(1) thì nó còn phụ thuộc vào thuật toán hash, hash chính là trái tim của HashTable, thuật toán hash tốt nhất nếu đưa vào 2 key khác nhau thì phải hash ra kết quả khác nhau (hash(key1) != hash(key2)) - việc này ko phải dễ dàng và dường như là ko thể nếu phải lưu trữ nhiều phần tử, nhưng mà bài này chỉ là làm quen với HashTable thôi nên mình ko đi sâu vào các thuật toán hash ( 😂 thật ra là mình cũng ko biết nhiều thuật toán hash đâu).
-
Nhắc đến truy cập constant-time O(1) thì ta nghĩ ngay đến mảng. Thằng HashTable cũng làm được điều ấy vì under-the-hood của nó là mảng. Việc hash(key) thực chất là việc chuyển từ string sang dạng số chính là index để truy cập mảng.
Idea: hashTable['me'] = 'you' ~= hash('me') = i && arr[i] = 'you'
-
Việc 2 key khác nhau mà hash ra cùng 1 kết quả (hash(key1) == hash(key2)) sẽ dẫn đến "thảm họa" (collision). Collision là điều tất yếu sẽ xảy ra trong HashTable, thuật toán hash "dở" thì collision xảy ra càng thường xuyên. Collision làm cho HashTable kém hiệu quả hơn so với những gì mà nó được kỳ vọng. Thảm họa sẽ xảy ra cho nên ta phải có kịch bản để đối phó với nó, theo mình biết là có 3 cách để đối phó với collision đó là : dùng Nối chuỗi, Dịch chuyển index và Thay đổi kích thước động. Việc 2 keys khác nhau cho ra cùng một hashcode nên ta phải lưu trữ cả key và value trong 1 phần tử thuộc HashTable mình gọi nó là HashNode(key, value).
-
Nối chuỗi (dùng Linked-List) : các Node có cùng key khi thêm vào HashTable sẽ được nối vào cùng 1 Linked-List (Worst case là tất cả phần tử thêm vào HashTable đều nằm cùng 1 Linked-List (truy cập sẽ là O(n)) => đây là do thuật toán hash "dở")
-
Dịch chuyển index : nếu hash ra một index mà arr[index] != undefined hoặc null (arr[index] đã tồn tại Node khác rồi) thì ta gán index += 1 đến khi nào mà arr[index] == undefined hoặc null. (Worst-case là thêm vào phần tử bạn phải loop đến chỗ mà chưa chứa phần tử nào => O(n), tương tự khi truy cập cũng phải loop đến chỗ phần tử đấy. Again thắng bại tại thằng hash)
-
Thay đổi kích thước động : cái này giống với dynamic array khi một phần tử được thêm vào nếu mà index của nó đã có phần tử Node khác rồi thì nó sẽ tăng kích thước mảng nên rồi hash lại cho các phần tử cũ cho đến chỗ index khác (thuật toán hash này thường thì sẽ phụ thuộc vào yếu tố ngoài như kích thước mảng... nên kích thước mảng thay đổi => kết quả hash sẽ thay đổi.) kích thước mảng tăng lên đồng nghĩa với việc nhiều chỗ trống hơn => collision ít hơn. (Ta có thể thấy luôn nhược điểm của thằng này là nó sẽ tạo ra nhiều ô trống hơn, lãng phí bộ nhớ, và khi thay đổi kích thước mảng lại phải hash lại các phần tử cũ.)
-
Mỗi kịch bản đối phó collision đều có ưu và nhược điểm (Itachi nói vẫn cấm có sai), ko kịch bản nào hoàn hảo cả. Cá nhân mình thì hay dùng Linked-List hơn nên là ở bài này mình chỉ implement HashTable với kịch bản xử lý collision bằng Linked-List.
Source Code
- Bạn có thể thay Linked-List bằng mảng để nhìn rõ hơn cách hoạt động.
- Hàm hash() ở đây mình dùng phép chia lấy dư cho size của mảng (đơn giản, dễ hình dung), bạn có thể áp dụng hàm hash() cho kịch bản dynamic array thay vì dùng LinkedList
// Implementation of LinkedList
class LinkedListNode {
constructor(val, next=null){
this.val = val
this.next = next
}
}
class LinkedList {
constructor(node=null){
this.head = this.tail = node
}
add(val){
const node = new LinkedListNode(val)
if (this.head === null){
this.head = this.tail = node
}
else{
this.tail.next = node
this.tail = node
}
}
}
// Implementation of HashTable
class HashNode {
constructor(key, value){
this.key = key
this.value = value
}
}
class HashTable {
constructor(size){
this.arr = [...new Array(size)].map(() => new LinkedList())
this.size = size
}
hash(key){
let sum = 0
for (let i of key) sum += i.charCodeAt(0)
return sum % this.size
}
add(key, value){
const idx = this.hash(key)
const linkedList = this.arr[idx]
let currentNode = linkedList.head
let exits = false
while (currentNode !== null){
if (currentNode.val.key === key) {
currentNode.val.value = value
exits = true
break
}
currentNode = currentNode.next
}
if (!exits) this.arr[idx].add(new HashNode(key, value))
}
get(key){
const idx = this.hash(key)
const linkedList = this.arr[idx]
let currentNode = linkedList.head
while (currentNode !== null){
if (currentNode.val.key === key) return currentNode.val.value
currentNode = currentNode.next
}
return undefined
}
has(key){
return this.get(key) !== undefined
}
}
let tbl = new HashTable(10)
tbl.add('tulen', 'knightz')
tbl.add('eultn', 'name') // same hashcode with 'tulen' above
tbl.add('hello', 'world')
tbl.add('me', 20)
tbl.add('me', 90)
console.log(tbl.get('tulen')) // knightz
console.log(tbl.has('velo')) // false
console.log(tbl.has('hello')) // true
console.log(tbl.get('hello')) // world
console.log(tbl.get('me')) // 90